ATProto
Bluesky and the AT Protocol - Usable Decentralized Social Media
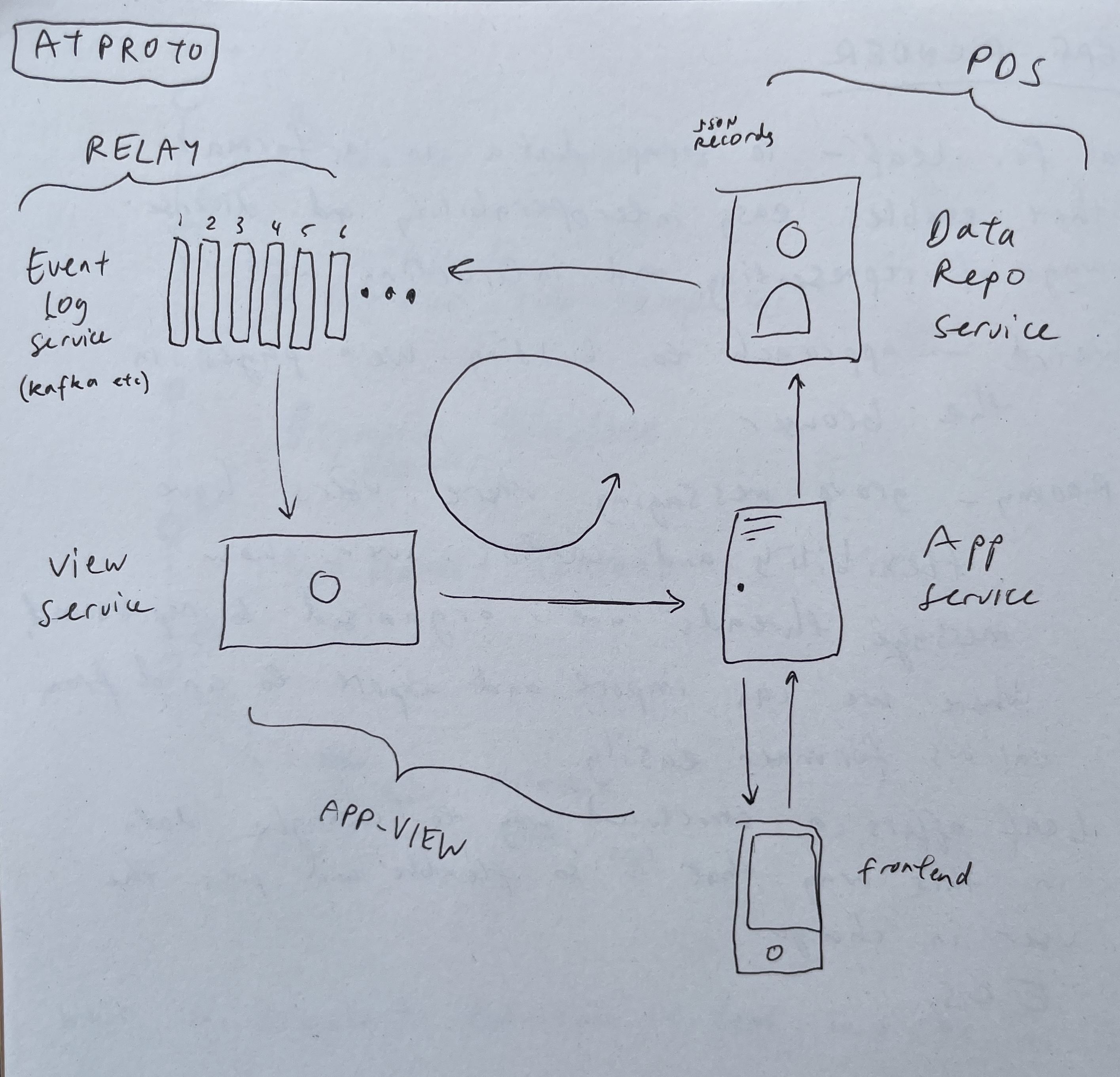
System Architecture
Merkle Search Trees
Are used for…
1. Representing Repos
Each ATProto user has a personal repo, a log of their content (posts, profile info, likes, etc.). This repo is:
-
An append-only log of commits
-
Where each commit contains a root hash of the MST
So the MST represents the current state of the repo, mapping keys like:
app.bsky.feed.post/3jkxga4k3...
app.bsky.actor.profile/selfto content records.
2. Efficient Sync
When two peers (or a client and PDS) want to sync:
- They compare MST root hashes
- If different, they do a tree walk, comparing child hashes to identify differences
- Only changed subtrees or records are transferred
This is much faster and lighter than sending full snapshots.
3. Inclusion Proofs
Because the MST is a Merkle tree, you can do:
- Proofs of inclusion (e.g. “This post exists in the repo at this commit”)
- Proofs of non-inclusion (e.g. “No record exists at this key”)
This is critical for verifiable data hosting, especially if PDSs or clients don’t trust each other fully.
🧠 Implementation Details
- Keys in the tree are lexicographically ordered strings (like
"app.bsky.feed.post/...") - Under the hood, it uses a binary search tree with hash links, not a trie or flat Merkle tree
- The hashing is content-addressed, using CID-style hashes
🧪 Practical Example
When you post something:
- The post is assigned a URI like:
at://did:plc:xyz/app.bsky.feed.post/abc123 - A record is created and added to the repo
- The MST is updated to include this new key
- A new commit is created with a pointer to the new MST root
- The commit is pushed to your PDS or other peers
📦 Summary
| Feature | Role of Merkle Search Tree in ATProto |
|---|---|
| Data organisation | Maps record keys to data efficiently |
| Integrity | Each commit signs the root hash of the MST |
| Sync | Allows diffing and fetching only changed data |
| Proofs | Enables verifiable inclusion/exclusion |
| If you’re interested in the actual implementation, it’s written in TypeScript here: | |
| 👉 atproto/packages/repo/src/mst |
is this taking into account changes as of sync v1.1 https://github.com/bluesky-social/proposals/tree/main/0006-sync-iteration ?
Good catch. The explanation I gave was mostly based on Sync v1. The new Sync v1.1 proposal (from the ATProto proposal repo) does change the role of Merkle Search Trees in a few key ways. Here’s a concise breakdown of what has changed and what remains:
🔧 What’s changed in Sync v1.1 (ATProto Proposal 0006)?
1. ==MSTs are no longer used for sync diffs==
- Before (v1.0): Diffing between commits was done by comparing MSTs.
- Now (v1.1): Sync diffs use a CAR file stream based on causal ordering of writes, not tree diffs.
- The MST still exists, but it’s no longer the main mechanism for sync.
Quote from proposal:
“Rather than performing a diff between MSTs, we instead stream the log of records, with the minimal set of records needed to represent the difference between two commits.”
2. Sync now uses a new syncGetRepoUpdates endpoint
- This streams all changes between two commit CIDs.
- Records are streamed in causal (topological) order, not sorted by key.
- This allows efficient reconstruction of state without relying on tree diffs.
3. No longer strictly ordering by key
- Previously, MSTs enforced strict key ordering, which was baked into the sync logic.
- With v1.1, ordering by key is no longer central—ordering is instead by record write order (commit history).
🪵 So what’s the role of MSTs now?
✅ Still used:
- As a content-addressable map in each commit
- For verifying the state of a repo at a commit
- For inclusion/exclusion proofs (e.g. proving “this key existed at this commit”)
❌ No longer used:
- For sync diffing between commits
- For generating record streams
🧠 Summary of Sync v1.1 Changes
| Feature | Sync v1 | Sync v1.1 |
|---|---|---|
| Sync diffing | MST diff | Causal stream of records |
| Ordering | By key | By causal write order |
| Inclusion proofs | MST-based | Still MST-based |
| State verification | MST root hash in commit | Still true |
| Key data structure | MST | Still used, but not for syncing |
💡 Implication
If you’re building anything that consumes or syncs repos:
- You should implement or expect the new streaming sync model
- But MSTs still matter for verifying data integrity, or for doing repo “audits”
Let me know if you want help parsing the syncGetRepoUpdates implementation or wiring it up to a CAR file stream parser.
Qand the streaming is from PDSs, right? is this endpoint defined on the PDS?
Yes — the syncGetRepoUpdates endpoint is implemented on the PDS (Personal Data Server).
✅ Confirmed in Sync v1.1
The syncGetRepoUpdates endpoint:
-
Is served by PDSs.
-
Replaces the need for clients or other PDSs to walk MSTs for diffs.
-
Streams changes (records and their metadata) between two commits in a DAG, using causal order.
From the spec (proposal 0006):
“The PDS exposes a syncGetRepoUpdates endpoint that streams a minimal CAR file representing the causal difference between two commits.”
This means:
-
Clients (or other PDSs) send a request like:
GET /xrpc/com.atproto.sync.getRepoUpdates?did=...&from=...&to=... -
The response is a CAR stream (Content Addressable aRchive format), representing just the diffs.
-
The sync logic is now simpler, requiring only commit DAG traversal and CAR parsing, not tree diffing.
🧱 So in short:
| Component | Role |
|---|---|
syncGetRepoUpdates | XRPC method defined on PDS |
| Response | CAR stream of DAG nodes (records, blocks) |
| Diffing logic | Moved from client-side MST diffing → to causal commit traversal in the PDS |
| MST | Still in each commit (for verifiability), but not used for diffing |
If you’re writing a sync client or mirror service, you now primarily need to:
-
Track heads (commit CIDs),
-
Call
syncGetRepoUpdates, -
Parse the returned CAR file and apply changes.
Let me know if you want an example of using this endpoint or building a minimal sync client.
Qand how do they calculate the set difference?
Great question — calculating the set difference (i.e. “what changed between commit A and commit B?”) in Sync v1.1 no longer involves walking Merkle Search Trees. Instead, it’s done by traversing the commit DAG between the two commits.
Here’s how the PDS calculates the difference:
🔁 How the PDS Calculates the Set Difference
Given two commit CIDs: from and to, the PDS:
-
Finds the common ancestor commit of
fromandtoin the repo’s DAG.-
The repo is a causal DAG (similar to Git’s commit graph).
-
Finding the ancestor is similar to a lowest common ancestor problem.
-
-
Traverses the DAG forward from the ancestor to
to.-
This traversal gives a topological order of all commits that occurred after the ancestor.
-
This guarantees causal ordering of record mutations.
-
-
Accumulates record-level changes from those commits.
-
Each commit contains a set of record mutations (creates, updates, deletes).
-
These are bundled into a CAR file stream in the correct order.
-
-
Returns a CAR stream that:
-
Includes the blocks (records, commits) needed to reconstruct the repo state at
to, -
But only includes the minimal necessary changes from
fromtoto.
-
🧱 Data involved
Each commit block contains:
-
The commit metadata (author, timestamp, prev CID)
-
The CID of the new MST root (for integrity)
-
A list of record mutations (key + op + CID)
These mutations are used to build the final stream of changes.
💡 So the “set difference” is:
-
Not a set difference of keys in a tree, like before
-
It’s a difference in record mutations across commits between two points in the DAG
🧪 Example
Say we have:
A --- B --- C --- D
\
E --- FIf you request updates from C to F:
-
The PDS finds
Cas the ancestor -
It walks the path
C → E → F -
It accumulates record mutations from those commits
-
It packages the result into a CAR stream and returns that
✳️ Bonus: Why this is better than MST diffing
-
Works for non-linear histories (e.g. forks and merges)
-
Preserves record mutation order
-
Avoids needing to compare record keys directly
-
More efficient and less stateful for clients
Let me know if you want a diagram or code walkthrough of this traversal logic — it’s conceptually close to a topological sort on a DAG plus collecting node payloads.